Which steps are recommended best practices for prioritizing cluster keys in Snowflake? (Choose two.)
The following statements have been executed successfully:
USE ROLE SYSADMIN;
CREATE OR REPLACE DATABASE DEV_TEST_DB;
CREATE OR REPLACE SCHEMA DEV_TEST_DB.SCHTEST WITH MANAGED ACCESS;
GRANT USAGE ON DATABASE DEV_TEST_DB TO ROLE DEV_PROJ_OWN;
GRANT USAGE ON SCHEMA DEV_TEST_DB.SCHTEST TO ROLE DEV_PROJ_OWN;
GRANT USAGE ON DATABASE DEV_TEST_DB TO ROLE ANALYST_PROJ;
GRANT USAGE ON SCHEMA DEV_TEST_DB.SCHTEST TO ROLE ANALYST_PROJ;
GRANT CREATE TABLE ON SCHEMA DEV_TEST_DB.SCHTEST TO ROLE DEV_PROJ_OWN;
USE ROLE DEV_PROJ_OWN;
CREATE OR REPLACE TABLE DEV_TEST_DB.SCHTEST.CURRENCY (
COUNTRY VARCHAR(255),
CURRENCY_NAME VARCHAR(255),
ISO_CURRENCY_CODE VARCHAR(15),
CURRENCY_CD NUMBER(38,0),
MINOR_UNIT VARCHAR(255),
WITHDRAWAL_DATE VARCHAR(255)
);
The role hierarchy is as follows (simplified from the diagram):
ACCOUNTADMIN└─ DEV_SYSADMIN└─ DEV_PROJ_OWN└─ ANALYST_PROJ
Separately:
ACCOUNTADMIN└─ SYSADMIN└─ MAPPING_ROLE
Which statements will return the records from the table
DEV_TEST_DB.SCHTEST.CURRENCY? (Select TWO)

A user has the appropriate privilege to see unmasked data in a column.
If the user loads this column data into another column that does not have a masking policy, what will occur?
An Architect Is designing a data lake with Snowflake. The company has structured, semi-structured, and unstructured data. The company wants to save the data inside the data lake within the Snowflake system. The company is planning on sharing data among Its corporate branches using Snowflake data sharing.
What should be considered when sharing the unstructured data within Snowflake?
A company’s table, employees, was accidentally replaced with a new version.
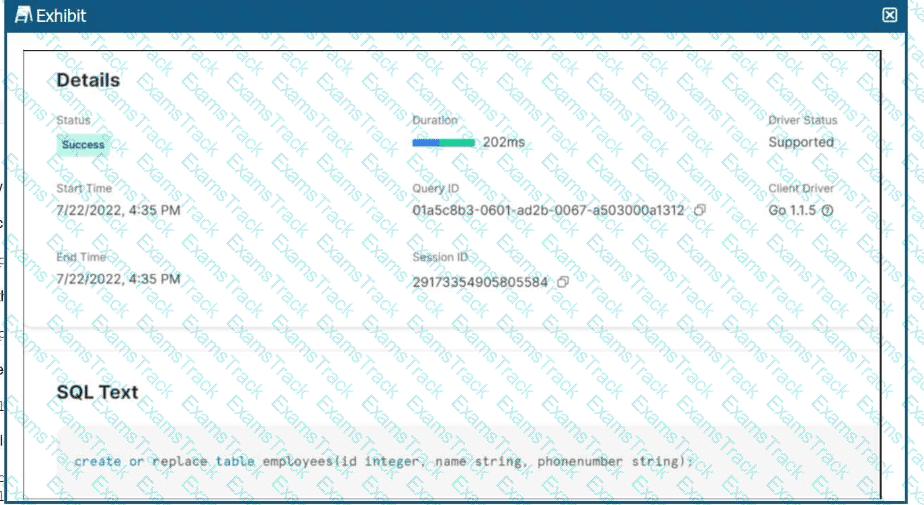
How can the original table be recovered with the LEAST operational overhead?
A table, EMP_ TBL has three records as shown:

The following variables are set for the session:

Which SELECT statements will retrieve all three records? (Select TWO).
A company has a table with that has corrupted data, named Data. The company wants to recover the data as it was 5 minutes ago using cloning and Time Travel.
What command will accomplish this?
An Architect wants to stream website logs near real time to Snowflake using the Snowflake Connector for Kafka.
What characteristics should the Architect consider regarding the different ingestion methods? (Select TWO).
A new table and streams are created with the following commands:
CREATE OR REPLACE TABLE LETTERS (ID INT, LETTER STRING) ;
CREATE OR REPLACE STREAM STREAM_1 ON TABLE LETTERS;
CREATE OR REPLACE STREAM STREAM_2 ON TABLE LETTERS APPEND_ONLY = TRUE;
The following operations are processed on the newly created table:
INSERT INTO LETTERS VALUES (1, 'A');
INSERT INTO LETTERS VALUES (2, 'B');
INSERT INTO LETTERS VALUES (3, 'C');
TRUNCATE TABLE LETTERS;
INSERT INTO LETTERS VALUES (4, 'D');
INSERT INTO LETTERS VALUES (5, 'E');
INSERT INTO LETTERS VALUES (6, 'F');
DELETE FROM LETTERS WHERE ID = 6;
What would be the output of the following SQL commands, in order?
SELECT COUNT (*) FROM STREAM_1;
SELECT COUNT (*) FROM STREAM_2;
When loading data from stage using COPY INTO, what options can you specify for the ON_ERROR clause?


