A data engineer has written a function in a Databricks Notebook to calculate the population of bacteria in a given medium.
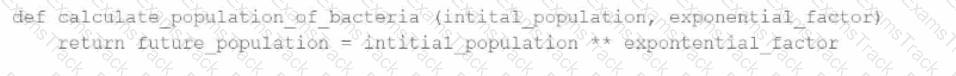
Analysts use this function in the notebook and sometimes provide input arguments of the wrong data type, which can cause errors during execution.
Which Databricks feature will help the data engineer quickly identify if an incorrect data type has been provided as input?
Which of the following is stored in the Databricks customer ' s cloud account?
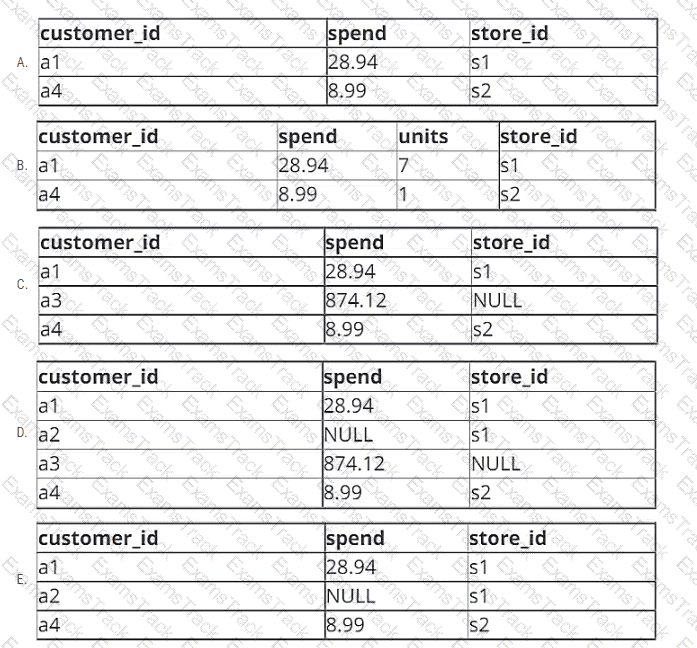
A data engineer is working with two tables. Each of these tables is displayed below in its entirety.

The data engineer runs the following query to join these tables together:

Which of the following will be returned by the above query?
A data engineer is decommissioning a sandbox schema in Unity Catalog. Some tables are ephemeral staging outputs that can be safely removed entirely, but a few tables point at shared cloud storage used by downstream jobs outside Databricks. The engineer must avoid deleting any shared files when cleaning up catalog objects.
How does Unity Catalog behave when dropping Managed vs External tables?
A data engineer is migrating pipeline tasks to reduce operational toil. The workspace uses Unity Catalog and is in a region that supports serverless. The engineer wants Databricks to auto-select instance types, manage scaling, apply Photon, and handle runtime upgrades automatically for job runs.
How should the data engineer meet this requirement while adhering to Databricks constraints?
A data engineer and data analyst are working together on a data pipeline. The data engineer is working on the raw, bronze, and silver layers of the pipeline using Python, and the data analyst is working on the gold layer of the pipeline using SQL The raw source of the pipeline is a streaming input. They now want to migrate their pipeline to use Delta Live Tables.
Which change will need to be made to the pipeline when migrating to Delta Live Tables?
A Delta Live Table pipeline includes two datasets defined using STREAMING LIVE TABLE. Three datasets are defined against Delta Lake table sources using LIVE TABLE.
The table is configured to run in Development mode using the Continuous Pipeline Mode.
Assuming previously unprocessed data exists and all definitions are valid, what is the expected outcome after clicking Start to update the pipeline?
Which of the following describes when to use the CREATE STREAMING LIVE TABLE (formerly CREATE INCREMENTAL LIVE TABLE) syntax over the CREATE LIVE TABLE syntax when creating Delta Live Tables (DLT) tables using SQL?
A data engineer has configured a Structured Streaming job to read from a table, manipulate the data, and then perform a streaming write into a new table.

The code block used by the data engineer is below:
Which line of code should the data engineer use to fill in the blank if the data engineer only wants the query to execute a micro-batch to process data every 5 seconds?
A Databricks workflow fails at the last stage due to an error in a notebook. This workflow runs daily. The data engineer fixes the mistake and wants to rerun the pipeline. This workflow is very costly and time-intensive to run.
Which action should the data engineer do in order to minimise downtime and cost?
|
PDF + Testing Engine
|
|---|
|
$49.5 |
|
Testing Engine
|
|---|
|
$37.5 |
|
PDF (Q&A)
|
|---|
|
$31.5 |
Databricks Free Exams |
|---|

|
Copyright © 2026 Examstrack. All Rights Reserved

TESTED 05 Jul 2026
