A data engineer is working with a large JSON dataset containing order information. The dataset is stored in a distributed file system and needs to be loaded into a Spark DataFrame for analysis. The data engineer wants to ensure that the schema is correctly defined and that the data is read efficiently.
Which approach should the data scientist use to efficiently load the JSON data into a Spark DataFrame with a predefined schema?
Given the schema:

event_ts TIMESTAMP,
sensor_id STRING,
metric_value LONG,
ingest_ts TIMESTAMP,
source_file_path STRING
The goal is to deduplicate based on: event_ts, sensor_id, and metric_value.
Options:
The following code fragment results in an error:
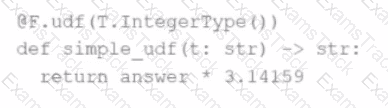
Which code fragment should be used instead?
A)

B)

C)

D)

A developer wants to test Spark Connect with an existing Spark application.
What are the two alternative ways the developer can start a local Spark Connect server without changing their existing application code? (Choose 2 answers)
A data engineer needs to write a DataFrame df to a Parquet file, partitioned by the column country, and overwrite any existing data at the destination path.
Which code should the data engineer use to accomplish this task in Apache Spark?
Which feature of Spark Connect is considered when designing an application to enable remote interaction with the Spark cluster?
A Data Analyst is working on the DataFrame sensor_df, which contains two columns:
Which code fragment returns a DataFrame that splits the record column into separate columns and has one array item per row?
A)

B)

C)

D)

21 of 55.
What is the behavior of the function date_sub(start, days) if a negative value is passed into the days parameter?
What is the relationship between jobs, stages, and tasks during execution in Apache Spark?
Options:
An engineer wants to join two DataFrames df1 and df2 on the respective employee_id and emp_id columns:
df1: employee_id INT, name STRING
df2: emp_id INT, department STRING
The engineer uses:
result = df1.join(df2, df1.employee_id == df2.emp_id, how='inner')
What is the behaviour of the code snippet?
|
PDF + Testing Engine
|
|---|
|
$49.5 |
|
Testing Engine
|
|---|
|
$37.5 |
|
PDF (Q&A)
|
|---|
|
$31.5 |
Databricks Free Exams |
|---|

|
Copyright © 2026 Examstrack. All Rights Reserved

TESTED 19 Jul 2026
