A company is planning to create several ML prediction models. The training data is stored in Amazon S3. The entire dataset is more than 5 ТВ in size and consists of CSV, JSON, Apache Parquet, and simple text files.
The data must be processed in several consecutive steps. The steps include complex manipulations that can take hours to finish running. Some of the processing involves natural language processing (NLP) transformations. The entire process must be automated.
Which solution will meet these requirements?
A company wants to share data with a vendor in real time to improve the performance of the vendor ' s ML models. The vendor needs to ingest the data in a stream. The vendor will use only some of the columns from the streamed data.
Which solution will meet these requirements?
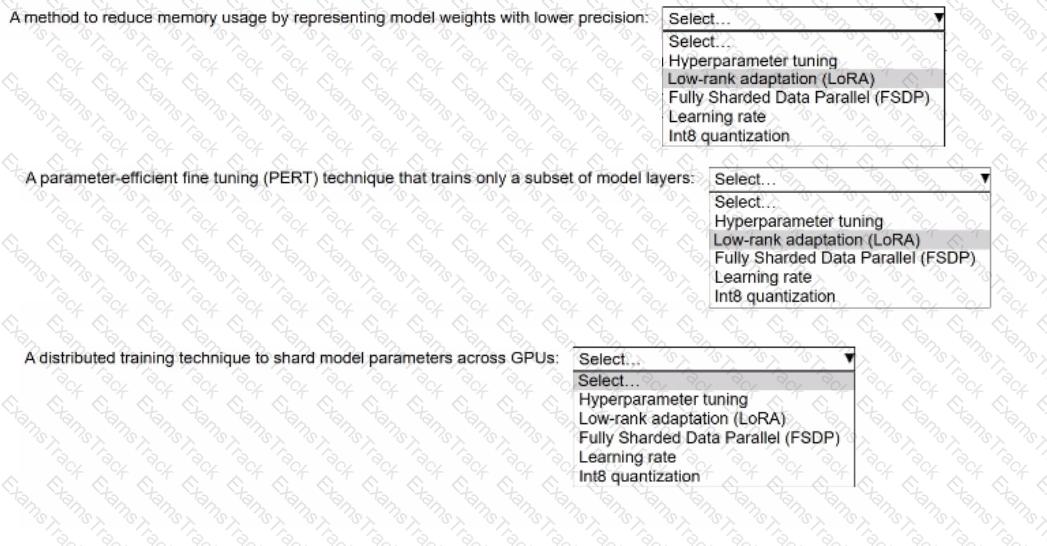
An ML engineer is using Amazon SageMaker JumpStart to fine-tune a Llama 3.2 model for text generation. The ML engineer is using an instruction-based fine-tuning method. The model uses 70 billion parameters.
Select the correct fine-tuning term from the following list to match each description. Select each term one time or not at all. (Select THREE.)
• Hyperparameter tuning
• Low-rank adaptation (LoRA)
• Fully Sharded Data Parallel (FSDP)
• Learning rate
• Int8 quantization
An ML engineer is developing a classification model. The ML engineer needs to use custom libraries in processing jobs, training jobs, and pipelines in Amazon SageMaker AI.
Which solution will provide this functionality with the LEAST implementation effort?
A company is creating an application that will recommend products for customers to purchase. The application will make API calls to Amazon Q Business. The company must ensure that responses from Amazon Q Business do not include the name of the company ' s main competitor.
Which solution will meet this requirement?
A company has a custom extract, transform, and load (ETL) process that runs on premises. The ETL process is written in the R language and runs for an average of 6 hours. The company wants to migrate the process to run on AWS.
Which solution will meet these requirements?
A financial company receives a high volume of real-time market data streams from an external provider. The streams consist of thousands of JSON records every second.
The company needs to implement a scalable solution on AWS to identify anomalous data points.
Which solution will meet these requirements with the LEAST operational overhead?
A company needs to run a batch data-processing job on Amazon EC2 instances. The job will run during the weekend and will take 90 minutes to finish running. The processing can handle interruptions. The company will run the job every weekend for the next 6 months.
Which EC2 instance purchasing option will meet these requirements MOST cost-effectively?
A company is developing an ML model by using Amazon SageMaker AI. The company must monitor bias in the model and display the results on a dashboard. An ML engineer creates a bias monitoring job.
How should the ML engineer capture bias metrics to display on the dashboard?
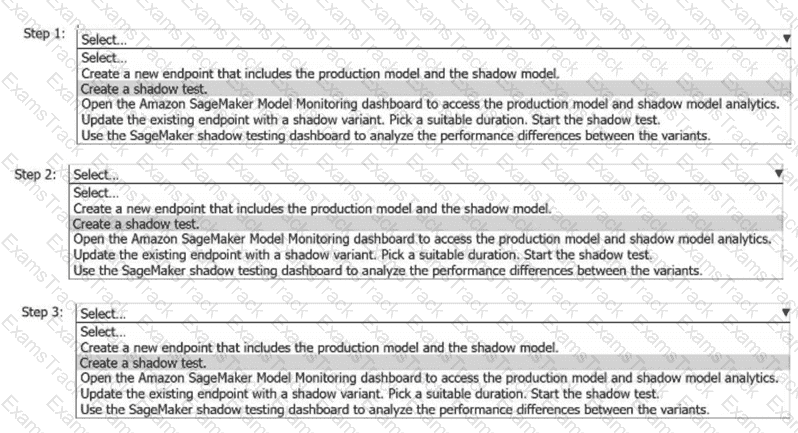
A company wants to evaluate a new ML model architecture to understand its performance before deploying the model to production. The company wants to use Amazon SageMaker AI shadow testing.
The company needs to analyze the performance metrics of the shadow model and the production model without affecting the existing production endpoint. The analysis must use real-time inference requests.
Select and order the correct steps to implement shadow testing and compare the model variants in SageMaker AI. Select each step one time or not at all (Select and order Three)
|
PDF + Testing Engine
|
|---|
|
$49.5 |
|
Testing Engine
|
|---|
|
$37.5 |
|
PDF (Q&A)
|
|---|
|
$31.5 |
Amazon Web Services Free Exams |
|---|

|
Copyright © 2026 Examstrack. All Rights Reserved

TESTED 07 Jul 2026


