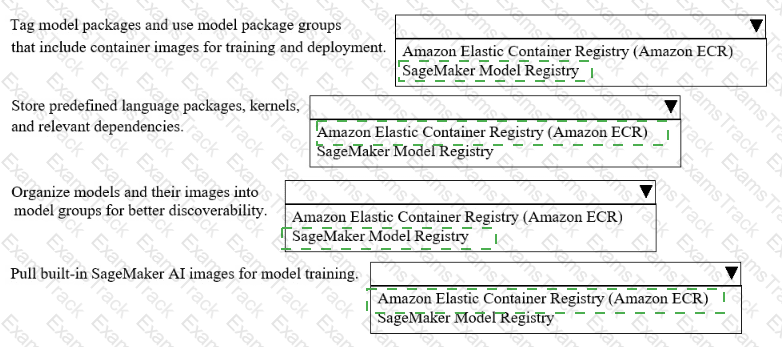
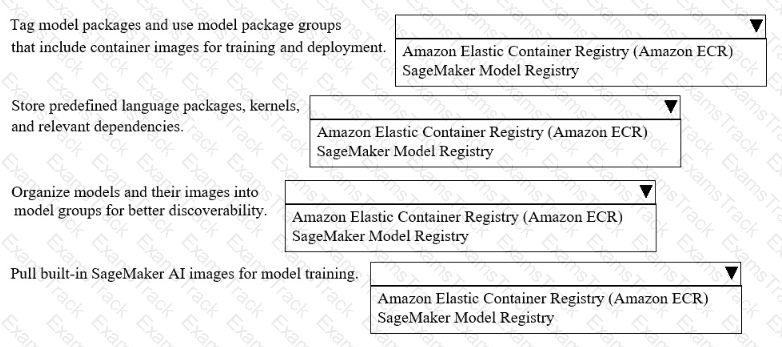
A company uses Amazon SageMakerAI to support ML workflows such as model training and deployment.
Select the correct registry from the following list to meet the requirements for each use case with the LEAST operational overhead. Each registry should be selected one or more times. (Select FOUR.)
• Amazon Elastic Container Registry (Amazon ECR)
• SageMaker Model Registry
An ML engineer is using Amazon SageMaker to train a deep learning model that requires distributed training. After some training attempts, the ML engineer observes that the instances are not performing as expected. The ML engineer identifies communication overhead between the training instances.
What should the ML engineer do to MINIMIZE the communication overhead between the instances?
A company needs to analyze a large dataset that is stored in Amazon S3 in Apache Parquet format. The company wants to use one-hot encoding for some of the columns.
The company needs a no-code solution to transform the data. The solution must store the transformed data back to the same S3 bucket for model training.
Which solution will meet these requirements?
A company is uploading thousands of PDF policy documents into Amazon S3 and Amazon Bedrock Knowledge Bases. Each document contains structured sections. Users often search for a small section but need the full section context. The company wants accurate section-level search with automatic context retrieval and minimal custom coding.
Which chunking strategy meets these requirements?
A company wants to predict the success of advertising campaigns by considering the color scheme of each advertisement. An ML engineer is preparing data for a neural network model. The dataset includes color information as categorical data.
Which technique for feature engineering should the ML engineer use for the model?
A company uses an ML model to recommend videos to users. The model is deployed on Amazon SageMaker AI. The model performed well initially after deployment, but the model ' s performance has degraded over time.
Which solution can the company use to identify model drift in the future?
A company has an application that uses different APIs to generate embeddings for input text. The company needs to implement a solution to automatically rotate the API tokens every 3 months.
Which solution will meet this requirement?
A company is using an AWS Lambda function to monitor the metrics from an ML model. An ML engineer needs to implement a solution to send an email message when the metrics breach a threshold.
Which solution will meet this requirement?
A company regularly receives new training data from a vendor of an ML model. The vendor delivers cleaned and prepared data to the company’s Amazon S3 bucket every 3–4 days.
The company has an Amazon SageMaker AI pipeline to retrain the model. An ML engineer needs to run the pipeline automatically when new data is uploaded to the S3 bucket.
Which solution will meet these requirements with the LEAST operational effort?
A company is developing ML models by using PyTorch and TensorFlow estimators with Amazon SageMaker AI. An ML engineer configures the SageMaker AI estimator and now needs to initiate a training job that uses a training dataset.
Which SageMaker AI SDK method can initiate the training job?
|
PDF + Testing Engine
|
|---|
|
$49.5 |
|
Testing Engine
|
|---|
|
$37.5 |
|
PDF (Q&A)
|
|---|
|
$31.5 |
Amazon Web Services Free Exams |
|---|

|
Copyright © 2026 Examstrack. All Rights Reserved

TESTED 14 Jul 2026