Which of the following tools would you use to create a natural language processing application?
What is Word2vec?
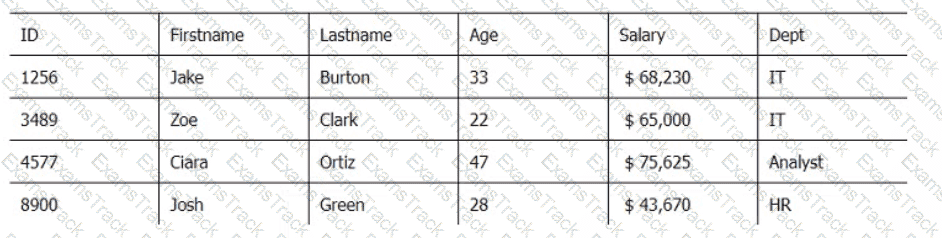
Below are three tables: Employees, Departments, and Directors.
Employee_Table
Department_Table
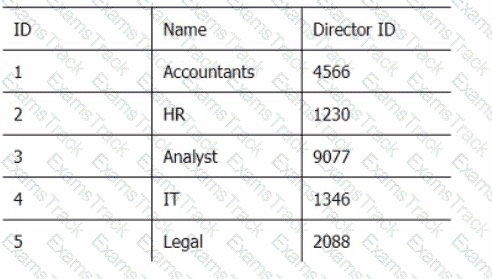
Director_Table
ID
Firstname
Lastname
Age
Salary
DeptJD
4566
Joey
Morin
62
$ 122,000
1
1230
Sam
Clarck
43
$ 95,670
2
9077
Lola
Russell
54
$ 165,700
3
1346
Lily
Cotton
46
$ 156,000
4
2088
Beckett
Good
52
$ 165,000
5
Which SQL query provides the Directors' Firstname, Lastname, the name of their departments, and the average employee's salary?
Which of the following is NOT an activation function?
Your dependent variable Y is a count, ranging from 0 to infinity. Because Y is approximately log-normally distributed, you decide to log-transform the data prior to performing a linear regression.
What should you do before log-transforming Y?
Which of the following models are text vectorization methods? (Select two.)
A classifier has been implemented to predict whether or not someone has a specific type of disease. Considering that only 1% of the population in the dataset has this disease, which measures will work the BEST to evaluate this model?
Which of the following is the correct definition of the quality criteria that describes completeness?
In a self-driving car company, ML engineers want to develop a model for dynamic pathing. Which of following approaches would be optimal for this task?
We are using the k-nearest neighbors algorithm to classify the new data points. The features are on different scales.
Which method can help us to solve this problem?
|
PDF + Testing Engine
|
|---|
|
$49.5 |
|
Testing Engine
|
|---|
|
$37.5 |
|
PDF (Q&A)
|
|---|
|
$31.5 |
CertNexus Free Exams |
|---|

|
Copyright © 2026 Examstrack. All Rights Reserved

TESTED 06 Jul 2026
